-

-
Description
-
Pricing
-
Features
-
Specification
-
Review
-
Compare
-
FAQs
-
Alternatives
 Get Free Advice
Get Free Advice
Get Quote
![]()
Description
Pricing
Features
Specification
Review
Compare
FAQs
Alternatives
Get Free Advice
Get Quote



Brand : The Apache Software Foundation
![]()
4.2 
4 Ratings
Have Questions?
Price On Request
Save Extra with 2 Offers

Users with registered businesses can purchase goods from merchants on the platform to satisfy their business needs. Users are not permitted to utilize any products acquired through the platform for resale, advertising, business, or further distribution.
For each purchase made, users will receive a Tax Invoice (or 'GST invoice') that includes specific details such as:
the GSTIN of the user associated with their registered business, and
the specified Entity Name for their business.
It should be noted that not all products are eligible for GST Invoice. Only the products displayed by participating sellers with the 'GST-based Invoice Available' callout on the product description page would qualify.
Certain goods and services are not eligible to get a GST Invoice, including items with VAS, i.e., Value Added Services (e.g., Total Mobile Protection/Assured Buyback) and those involving an exchange offer at the time of purchase.
Users must ensure the accuracy of the GSTIN, and business entity name provided for the GST Invoice. Requests for corrections into GST Invoice would not be accommodated by Techjockey.com or any Seller, and any issues arising from user-provided information are the sole responsibility of users.
Techjockey.com is not liable for the GST Invoice or any associated input tax credit. To efficiently claim an input tax credit, users should select the registered place of business address as per the GST authority's data and follow the provisions of the GST Act and rules.
To claim an input tax credit, the delivery and billing addresses must match. Furthermore, input tax credits will not be granted if the delivery address and GSTIN on the invoice are from different states. In case of incorrect GST details provided during the order placement, the order will be canceled automatically.
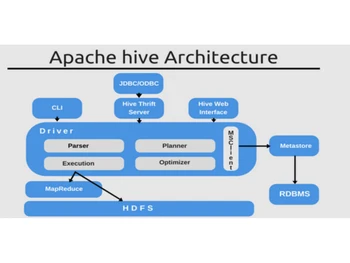
Apache Hive is an open-source data warehouse system built on top of Hadoop, facilitating querying and managing large datasets stored in distributed storage using a SQL-like language....Read more
 Safe & Secure
Safe & Secure  Assured Best Price
Assured Best Price 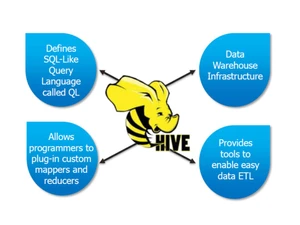
Data Analysis
It facilitates comprehensive data analysis via SQL-like queries for insights extraction from large datasets.
Merge
It allows merging datasets, enabling users to combine multiple data sources into a single dataset for analysis.
Data Filtering
It permits dataset filtering based on specific criteria, aiding data extraction and refinement.
Data Quality Management
It provides tools for managing data quality, ensuring the accuracy and reliability of analysis results.
Metadata Management
It offers features for managing metadata, enhancing organization and understanding of data assets.
Relational Database
It offers relational database capabilities, enabling manipulation of structured data using SQL-like queries.
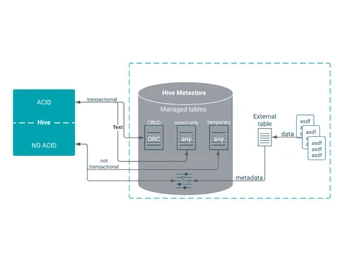
ACID
It supports ACID transactions, ensuring data integrity and reliability in database operations.
Data Compaction
It includes features for data compaction, optimizing storage efficiency by reducing redundant or unnecessary data.
| Brand Name | The Apache Software Foundation |
| Information | Apache Software Foundation provides organizational, legal and financial support for Apache open-source software projects. |
| Founded Year | 1999 |
| Director/Founders | Brian Behlendorf, Grant Ingersoll, Isabel Drost-Fromm, Jim Jagielski, Lars Eilebrecht, Patrick Stued |
| Company Size | 1-100 Employees |
| Other Products | Apache Flink, Apache HBase, Apache Jmeter, Apache Kafka, Apache Spark |

![]() 20,000+ Software Listed
20,000+ Software Listed
![]() Best Price Guaranteed
Best Price Guaranteed
![]() Free Expert Consultation
Free Expert Consultation
![]() 2M+ Happy Customers
2M+ Happy Customers





