Redis and Kafka are two powerful and popular tools in the realm of data management and processing. While both serve as key components in distributed systems, they are designed to address different aspects of data handling. In this quick comparison, we will explore the distinctive features of Redis and Kafka, highlighting their strengths in terms of data storage, messaging, fault tolerance, performance, and more.
Redis vs. Kafka: An Overview
Redis is an open-source, in-memory data structure store known for its high performance and versatility. It is designed to store and retrieve data quickly by keeping it entirely in memory, making it an ideal choice for caching, real-time analytics, session storage, and pub/sub messaging. It supports various datatypes such as strings, hashes, lists, sets, and sorted sets. Apart from that, it offers advanced features like replication, clustering, persistence options, and Lua scripting.
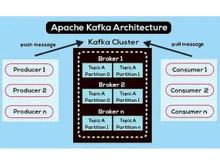
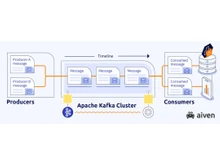
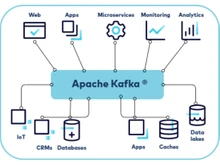
On the other hand, Apache Kafka is a distributed streaming platform that is designed to handle real-time data streams. It provides a highly fault-tolerant and durable system for publishing, subscribing, storing, and processing streams of records. It is known for its high throughput, low-latency message delivery, and the ability to parallelize message processing. Apart from that, Kafka is widely used for building real-time data pipelines, event sourcing, and stream processing applications.
Redis vs. Kafka: Key Differences
Here are a few differences between Redis as well as Apache Kafka, these include:
- Redis and other Redis alternatives are used for real-time analytics, session storage, and pub/sub messaging. Kafka is used for real-time data pipelines, event sourcing, and stream processing applications.
- Redis focuses on in-memory data storage and retrieval, while Kafka and a few Kafka alternatives emphasize fault tolerance and durable handling of large-scale data streams.
- Redis is known for high-speed data access and low-latency performance. In contrast, Kafka is known for high throughput and low-latency message delivery.
- Redis offers horizontal scalability enabling data distribution across multiple nodes. Kafka also supports horizontal scalability allowing you to handle increasing workloads.
- Setting up and configuring Kafka clusters and consumer groups is much more complex, especially in large-scale deployment scenarios. Redis involves less complexity in setup and configuration.
- Kafka is suited for handling large message sizes, including binary data and complex message formats. Redis has message size limitations due to its in-memory nature, and large messages need to be segmented.
Redis and Kafka: In Terms of Features
Below are some of the feature differentiations between Redis and Kafka. These include subscription, parallelism, message delivery, fault tolerance, and more.
- Parallelism: Kafka is designed to support the parallel processing of messages through its partitioning, replication, and consumer groups, allowing multiple consumers to process messages simultaneously. Redis, on the other hand, provides parallelism through its support for multiple clients and can handle concurrent operations, but is used for in-memory data storage and retrieval rather than parallel message processing.
- Subscription: Kafka supports multiple subscribers, allowing for parallel message consumption by different subscribers. In contrast, Redis supports publishing and subscribing to channels, allowing multiple subscribers to receive messages from the same channel.
- Message Delivery: Kafka guarantees at least one message delivery semantics and supports configurable delivery guarantees. While Redis doesn’t provide the same level of message delivery guarantees.
- Pub/Sub Support: Kafka offers inbuilt pub/sub support, enabling decoupled message publication and consumption. Redis, on the other hand, provides native support for pub/sub messaging, enabling publishers to broadcast messages to multiple subscribers through channels.
- Fault Tolerance: Kafka is designed with built-in fault tolerance features, such as data replication across brokers and configurable retention policies, ensuring data durability and fault tolerance. Redis offers fault tolerance through RDB snapshots, AOF logs, and master-slave replication. It ensures recovery from failures and maintains data integrity.
- Error Handling: Kafka helps in advanced error handling through configurable retries, dead-letter queues, and offset management. On the other hand, Redis offers basic error-handling capabilities.
Redis vs. Kafka: Message Retention
Kafka retains messages for a configurable period, allowing consumers to access their historical data based on the retention setting. Redis, on the other hand, doesn’t support message retention. Therefore, it doesn’t save any messages and can never be recovered.
Redis and Kafka: Category
Kafka is categorized as a distributed streaming platform designed for building real-time data pipelines and streaming applications. On the other hand, Redis is categorized as an in-memory data store and caching system and provides support for pub/sub messaging.
Redis or Kafka: Speed
Kafka is designed for high-throughput and low-latency message processing. Redis is known for its extremely low-latency performance, making it suitable for high-speed data access and caching.
Redis and Kafka: Amount of Data
Kafka is capable of handling large amounts of data and is well-suited for high-volume data streams. Redis helps store and access data in memory, so its capacity to handle data depends on available memory resources and is not much optimized for large-scale data storage.
Redis or Kafka: Use Cases
Use cases for Kafka include real-time data integration, stream processing, event sourcing, and log aggregation. On the other hand, use cases for Redis include caching, session store, real-time analytics, message queuing, and pub/sub messaging.
Redis or Kafka: Data Persistence
Kafka provides distributed data storage through its topic partitions and replication mechanisms, ensuring data persistence and fault tolerance. Redis offers multiple data persistence options, including snapshotting and AOF (append-only file) modes.
Redis and Kafka: Message Ordering
Kafka maintains message ordering within a partition, ensuring that messages within the same partition are processed in the order they were received. Redis pub/sub does not guarantee message ordering between different channels or between messages published on the same channel.
Redis and Kafka: Message Acknowledgment
Kafka provides options for message acknowledgment and offset management, allowing consumers to control the acknowledgment of processed messages. Redis does not have built-in message acknowledgment mechanisms.
Redis vs. Kafka: Language
Kafka is implemented in Java, making use of JVM (Java Virtual Machine). It also provides language bindings for other programming languages such as Python, Go, etc., through client libraries. On the other hand, Redis is implemented in ANSI C. Apart from that, it provides client libraries for various programming languages.
Verdict: Redis vs. Kafka
Overall, Redis and Kafka serve distinct purposes in the realm of data management and processing. Redis excels as an in-memory data store and caching system, offering high-speed data access, low-latency performance, and versatile data manipulation capabilities. It is well-suited for real-time analytics, session storage, and pub/sub messaging. On the other hand, Kafka works as a distributed streaming platform, with features like fault-tolerance and durable handling of large-scale real-time data streams with high throughput and low-latency message delivery. It is specifically designed for building real-time data pipelines, event sourcing, and stream processing applications.


 3 Ratings & 0 Reviews
3 Ratings & 0 Reviews